8. twitteR
No artigo de hoje, vamos conhecer a biblioteca twitteR e como minerar textos diretamente do Twitter. Para isso, você vai precisar cadastrar uma aplicação API no site do Twitter, para pegar credenciais e acessar a API do twitter de forma autenticada. Se você nunca criou uma aplicação no Twitter antes, clique neste link para ter informações básicas de como prosseguir antes deste tutorial. As etapas são simples:
- Criar uma conta de Developer no http://dev.twitter.com.
- Criar um TwitterApp, que é uma identificação da sua aplicação que acessará a API.
- Criar as Consumer Keys e Access Tokens, que são as chaves que você usará no seu código R para autenticar sua aplicação e ter acesso aos dados do Twitter.
Após obter as chaves, não se esqueça de instalar o pactoe twitteR e usufruir deste rico acesso a dados em tempo real.
Acessando a API
Após realizar os procedimentos acima, vamos ao R:
library(twitteR)
consumer_key <- "sua consumer_key"
consumer_secret <- "seu consumer_secret"
access_token <- "seu access_token"
access_secret <- "seu access_secret"Não se esqueça: estas 4 chaves/códigos você obtém no site developers do Twitter. Prosseguindo com a autenticação e, sem seguida, vamos pegar as hashtags que estão trending no Brasil, no momento que rodei esta análise:
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)## [1] "Using direct authentication"trends <- getTrends(23424768) # este número se refere ao Brasil.
head(trends$name, 10) # retorna as 10 primeiras hashtags.## [1] "#MasterChefBR" "#issaLGBTQ" "#issoaglobonaomostra"
## [4] "#Fantastico" "#BigLittleLies" "Silvio Santos"
## [7] "MÚSICAS QUE LEMBRAM" "Mary Louise" "Amazon Day"
## [10] "raça negra"Um aspecto importante é sobre o código usado na função getTrends(). Este número 23424768 é um código de localização padrão para o Brasil. Este código, conhecido como WOEID, é uma numeração única para diferentes regiões geográficas e podem compreender países, estados, municípios, etc. Você pode ler mais a respeito dele aqui.
Escrevi esta análise no Domingo à Noite, então é esperado que alguns programas dominicais de TV estejam nos trending topics, como #MasterChefBR, #Fantastico e Silvio Santos. Agora temos alguns tópicos para explorar e, para isso, vamos usar a função searchTwitter() para buscar os últimos 200 tweets sobre #MasterChefBR, por exemplo:
library(dplyr)
tweets <- searchTwitter('#MasterChefBR', n = 200, resultType="recent", lang="pt-br") %>%
twListToDF() %>% # Converte o formato lista para data frame
as_tibble() %>% # Converte no formato tidy
select(text) # Seleciona apenas a coluna que contém o conteúdo de texto
head(tweets, 10)## # A tibble: 10 x 1
## text
## <chr>
## 1 RT @EthuuWith2U: Lorena na primeira prova // Lorena na prova de elimina…
## 2 RT @anjosjaun: #MasterchefBR o coentro se preparando novamente pra entr…
## 3 "RT @aucalusto: eu escrevendo artigo científico\n\n#MasterChefBR https:…
## 4 RT @Vitortarifa_: #MasterChefBR A Haila nesse exato momento em cima do …
## 5 RT @leonardojrod: O HELTON TINHA DITO TUDO O QUE O JACQUIN DISSE DE NOV…
## 6 RT @siiqqueira: Vamo time amarelo #MasterChefBR
## 7 RT @anjosjaun: #MasterchefBR o coentro se preparando novamente pra entr…
## 8 "RT @anandaoliveiraf: Lorena: Não dá as flores pra eles pq senão vai fi…
## 9 Meu domingo à noite não vai ter a mesma beleza. Saudade do Mauad já....…
## 10 RT @anjosjaun: #MasterchefBR o coentro se preparando novamente pra entr…Com esta linha de código conseguimos fazer a interface entre o pacote twitteR e já convertemos o conteúdo de texto dos tweets no formato tidy, que facilitará as análises de dados usando a biblioteca tidytext. Porém, antes de prosseguir precisaremos aprofundar em mais um aspecto do pré-processamento de dados: a remoção de links, mentions e RTs.
Pré-processamento de dados do Twitter
Como você pode ver no exemplo acima, o compartilhamento de URLs, as mentions (quando alguém responde citando o usuário de alguém com @) e RTs são comportamentos muito comuns. Desta forma, precisamos remover estes textos desnecessários que trariam ruído para nossa análise. Para isso vamos usar expressões regulares com a função gsub() nativa do R.
Expressão regular é uma linguagem onde é possível especificar padrões a serem buscados em conjuntos de textos ou códigos. Você pode encontrar mais informações técnicas neste artigo da Wikipedia. Para simplificar, já darei as expressões simples:
texto = "RT @andersonjosepor: O programa acabou faz tempo e ainda tem gent aq #MasterChefBR https://t.co/Zj9UR8DMBF"
texto %>%
gsub(pattern = "RT ",replacement = "") %>% # Remove RT simples
gsub(pattern = "http\\S+\\s*",replacement = "") %>% # Remove URLs
gsub(pattern = "@\\w+: ",replacement = "") # Remove @mentions## [1] "O programa acabou faz tempo e ainda tem gent aq #MasterChefBR "Frequência de termos para #MasterChefBR
Agora que aprendemos esta etapa adicional de tratamento, vamos juntar com o que já aprendemos sobre análise de termos relevantes usando frequência simples e ver o que temos para #MasterChefBR:
library(tidytext)
library(tm)
library(ptstem)
library(ggplot2)
# Pré-processamento
tweets <- tweets$text %>%
gsub(pattern = "RT ",replacement = "") %>% # Remove RT simples
gsub(pattern = "http\\S+\\s*",replacement = "") %>% # Remove URLs
gsub(pattern = "@\\w+: ",replacement = "") %>% # Remove @mentions
ptstem() # Retorno ao radical
# Formato tidy
tidytweets <- tibble(linha = 1:length(tweets), tweet = tweets)
tidytweets %>%
unnest_tokens(palavra, tweet) %>%
filter(!palavra %in% stopwords(kind = "pt")) %>%
filter(!palavra == "masterchefbr") %>% # Remove #MasterChefBR pois é a palavra-chave.
count(palavra, sort = TRUE) %>%
mutate(palavra = reorder(palavra, n)) %>%
top_n(10) %>%
ggplot(aes(palavra, n)) +
geom_col() +
xlab(NULL) +
coord_flip()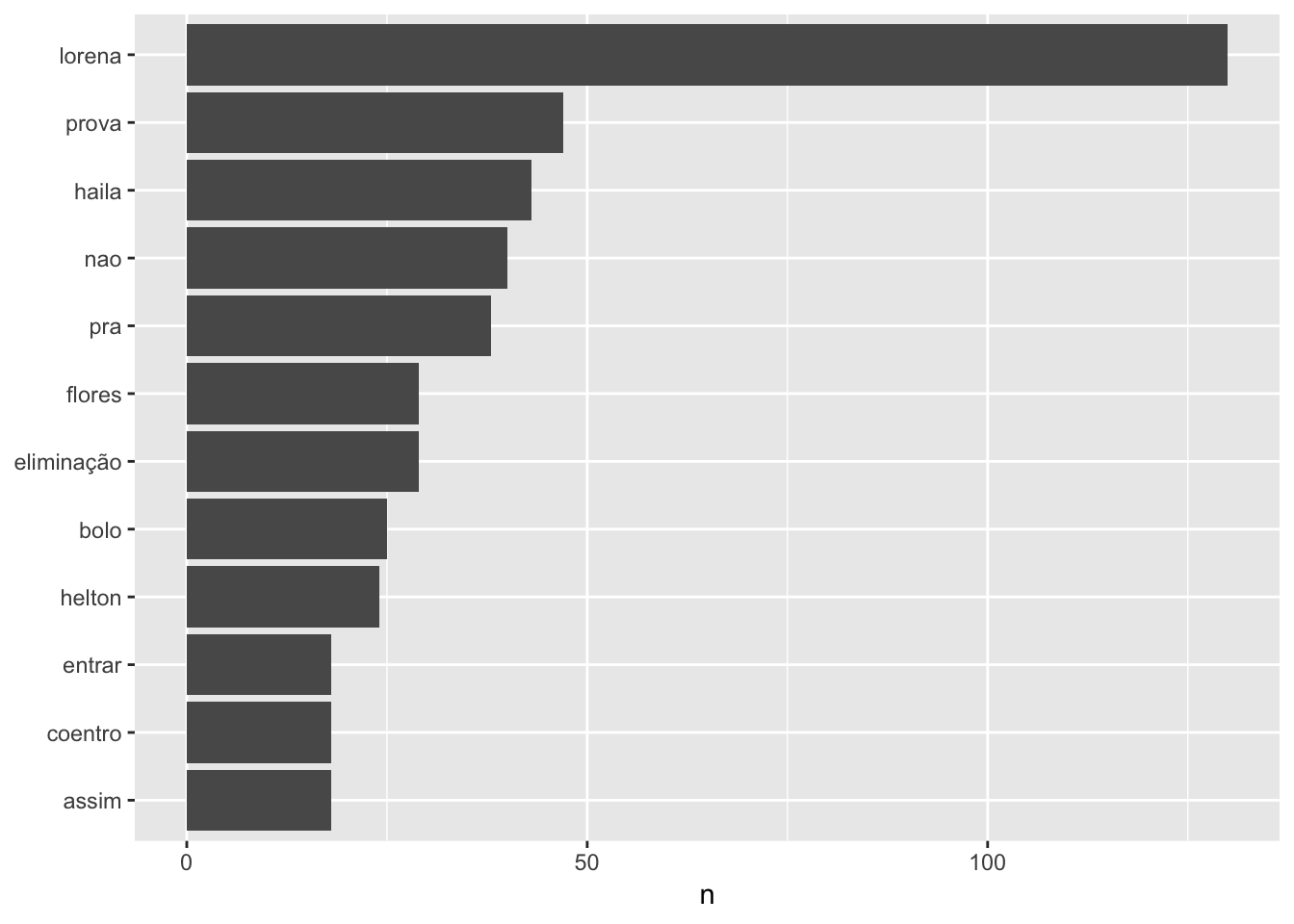
Recapitulando
- Utilizamos a biblioteca
twitteRpara buscar uma lista de trending topics no Twitter no Brasil, com a funçãogetTrends(). - Buscamos os últimos 200 tweets da hashtag mais citada: #MasterChefBR.
- Aplicamos técnicas de pré-processamento específicas para textos do twitter: remoção de RTs, remoção de URLs e remoção de @mentions.
- Aplicamos as técnicas tradicionais de pré-processamento: retorno ao radical, tokenização, filtro de stopwords e removemos a #MasterChefBR também, dado que este foi o termo buscado.
- Cálculo de frequências e gráfico usando
ggplot().
Note que dependendo da sua fonte de dados, você precisará fazer tratamentos específicos para garantir que a informação que você irá tirar dos conteúdos faça sentido e não fique viesada para especificidades da plataforma.
Bons estudos e até a próxima!