6. tf-idf
Neste artigo você irá conhecer uma metodologia chamada tf-idf que serve para selecionar as palavras mais importantes de um texto baseado em sua frequência. No entanto, esta metodologia leva em consideração que palavras muito frequentes em diversos documentos diferentes não trazem tanta informação relevante para o contexto (como as stopwords, por exemplo) e, para tanto, considera diferentes pesos para elas. Segundo este artigo da Wikipedia:
O valor tf–idf de uma palavra aumenta proporcionalmente à medida que aumenta o número de ocorrências dela em um documento, no entanto, esse valor é equilibrado pela frequência da palavra no corpus. Isso auxilia a distinguir o fato da ocorrência de algumas palavras serem geralmente mais comuns que outras.
Exemplo do artigo anterior
Para ilustrar esta metodologia, vou puxar do artigo anterior o mesmo conjunto de textos sobre diferentes modalidades esportivas.
library(dplyr)
library(rvest)
library(tidytext)
library(tm)
library(ptstem)
futebol <- "https://pt.wikipedia.org/wiki/Futebol" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
voleibol <- "https://pt.wikipedia.org/wiki/Voleibol" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
handebol <- "https://pt.wikipedia.org/wiki/Andebol" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
basquetebol <- "https://pt.wikipedia.org/wiki/Basquetebol" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
# Criando a tabela única usando bind_rows() para empilhar todos os parágrafos
esportes <- bind_rows(
tibble(modalidade = "futebol", paragrafos = futebol),
tibble(modalidade = "voleibol", paragrafos = voleibol),
tibble(modalidade = "handebol", paragrafos = handebol),
tibble(modalidade = "basquetebol", paragrafos = basquetebol)
)
# Pré-processamento
esportes$paragrafos <- ptstem(esportes$paragrafos) # Retorno ao radical
# Processamento
esportes_palavras <- esportes %>%
unnest_tokens(palavra, paragrafos) %>%
filter(!palavra %in% stopwords(kind = "pt")) %>%
group_by(modalidade) %>%
count(palavra, sort = TRUE)
head(esportes_palavras)## # A tibble: 6 x 3
## # Groups: modalidade [3]
## modalidade palavra n
## <chr> <chr> <int>
## 1 futebol futebol 175
## 2 futebol jogado 160
## 3 futebol é 93
## 4 basquetebol jogado 56
## 5 voleibol jogado 55
## 6 basquetebol bola 54Até este ponto não há nada de novo. Se você estiver um pouco perdido, por favor, acesse o artigo anterior para entender os detalhes sobre os comandos acima.
Calculando tf-idf
A função bind_tf_idf() do pacote tidytext calculará para nós os parâmetros e o valor final de tf-idf de forma simples e direta:
esportes_palavras <- esportes_palavras %>%
bind_tf_idf(palavra, modalidade, n)
esportes_palavras## # A tibble: 3,374 x 6
## # Groups: modalidade [4]
## modalidade palavra n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 futebol futebol 175 0.0312 0 0
## 2 futebol jogado 160 0.0286 0 0
## 3 futebol é 93 0.0166 0 0
## 4 basquetebol jogado 56 0.0357 0 0
## 5 voleibol jogado 55 0.0272 0 0
## 6 basquetebol bola 54 0.0344 0 0
## 7 futebol mundo 54 0.00964 0.288 0.00277
## 8 futebol partida 54 0.00964 0 0
## 9 basquetebol é 53 0.0338 0 0
## 10 futebol fifa 53 0.00946 1.39 0.0131
## # … with 3,364 more rowsNote que, para cada modalidade, temos os valores de tf, idf, e tf-idf, para cada palavra. Vejamos o exemplo de jogado:
Essa palavra aparece na lista acima para as modalidades futebol, voleibol e basquetebol. Provavelmente deve existir para handebol também.
Ela apresenta diferentes valores de tf, ou seja, aparecem com diferentes frequências em cada uma das modalidades.
No entanto, todas elas apresentam valor de idf iguais a 0. Isso acontece pois essa métrica apresenta o inverso da frequência entre os documentos, o que significa que esta palavra aparece em todas as modalidades. Portanto, não é uma palavra específica de uma só modalidade. Isso também acontece com outros termos comuns a esportes em geral como bola e partida.
Por fim, vamos fazer o gráfico com as palavras mais relevantes usando tf-idf por modalidade:
library(ggplot2)
esportes_palavras %>%
arrange(desc(tf_idf)) %>% # Ordenando os termos por tf_idf dentro de cada modalidade
top_n(7) %>%
ggplot(aes(palavra, tf_idf)) +
geom_col() +
facet_wrap(~modalidade, ncol = 2, scales = "free") +
xlab(NULL) +
coord_flip()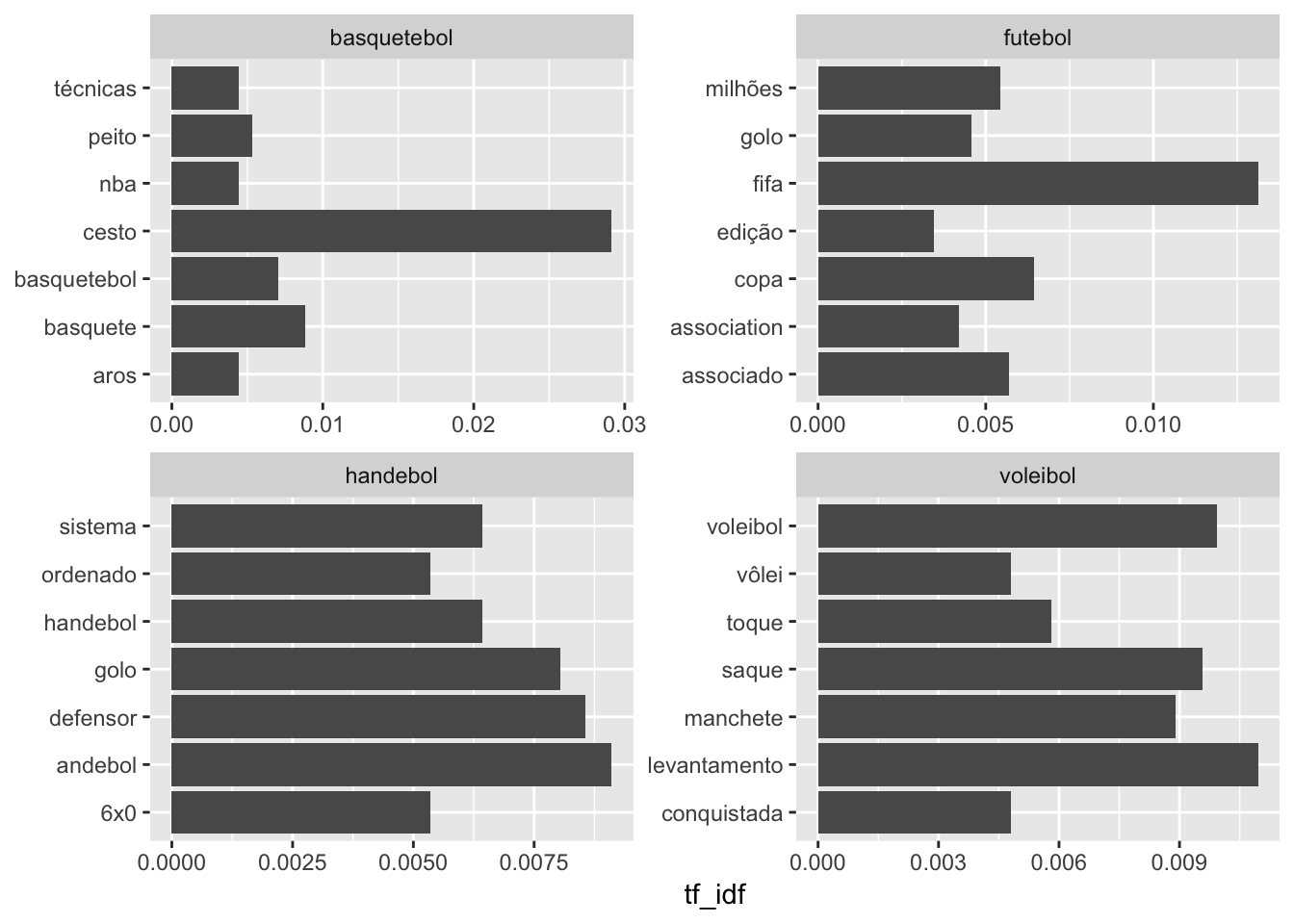
Note que os resultados acima são bem mais interessantes do que a simples frequência de palavras do artigo anterior. Especialmente para o voleibol, por exemplo, com os termos técnicos de cada fundamento/movimento do jogo.
Esta metodologia é muito interessante para se criar dicionários de palavras importantes dado o contexto dos textos inseridos na análise. Uma aplicação, por exemplo, seria criar dicionários para classificar documentos em categorias. Se você realizar esse cálculo de termos relevantes em um conjunto de textos pré-classificados (que você pode chamar de conjunto de treinamento - ou parametrização), poderá utilizar um sistema de classificação de novos textos de acordo com o tema.
Até o próximo artigo! Bons estudos!