7. Similaridade
Neste artigo, vamos ver como identificar o grau de similaridade (ou correlação) entre conjuntos de texto.s Isso pode nos ajudar a entender como palavras podem identificar conteúdos semelhantes e quantificar este grau de similaridade.
Base de Textos
Vamos iniciar com uma série de comandos já falados em artigos anteriores onde usamos o pacote rvest para minerar conteúdos de websites. Nossa fonte, para este artigo, é o site do UOL Esporte com 3 artigos sobre futebol e 3 artigos sobre voleibol. Vamos testar esta metodologia para entender o quanto estes textos são similares entre si.
No trecho de código a seguir temos o web-scrapping e o pré-processamento de dados textuais que já abordamos nos artigos anteriores, bem como a transformação no formato tidytext.
library(dplyr)
library(rvest)
library(tidytext)
library(tm)
library(ptstem)
fut1 <- "https://esporte.uol.com.br/futebol/ultimas-noticias/2019/06/25/selecao-brasileira-faz-mais-um-treino-sem-cassio-mas-com-fernandinho.htm" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
fut2 <- "https://esporte.uol.com.br/futebol/ultimas-noticias/2019/06/25/demora-de-ramires-para-se-apresentar-no-palmeiras-irrita-torcedores-na-web.htm" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
fut3 <- "https://esporte.uol.com.br/futebol/ultimas-noticias/2019/06/25/cruzeiro-diz-adeus-a-lucas-silva-que-voltara-de-emprestimo-ao-real-madrid.htm" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
vol1 <- "https://saidaderede.blogosfera.uol.com.br/2019/06/22/em-jogo-nervoso-selecao-masculina-erra-muito-e-bate-a-alemanha-no-sufoco/" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
vol2 <- "https://saidaderede.blogosfera.uol.com.br/2019/06/23/com-forca-do-elenco-selecao-masculina-se-impoe-e-vence-equipe-russa/" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
vol3 <- "https://saidaderede.blogosfera.uol.com.br/2019/06/21/brasil-supera-falhas-na-recepcao-e-vence-a-bulgaria-na-liga-das-nacoes/" %>%
read_html() %>%
html_nodes("p") %>%
html_text()
# Criando a tabela única usando bind_rows() para empilhar todos os parágrafos
esportes <- bind_rows(
tibble(modalidade = "fut1", paragrafos = fut1),
tibble(modalidade = "fut2", paragrafos = fut2),
tibble(modalidade = "fut3", paragrafos = fut3),
tibble(modalidade = "vol1", paragrafos = vol1),
tibble(modalidade = "vol2", paragrafos = vol2),
tibble(modalidade = "vol3", paragrafos = vol3)
)
# Pré-processamento
esportes$paragrafos <- ptstem(esportes$paragrafos) # Retorno ao radical
# Processamento
esportes_palavras <- esportes %>%
unnest_tokens(palavra, paragrafos) %>%
filter(!palavra %in% tm::stopwords(kind = "pt")) %>%
group_by(modalidade) %>%
count(palavra, sort = TRUE)Correlação entre Textos
Para entender a similaridade entre os textos, podemos usar a correlação entre as palavras utilizadas nos textos. Para isso, utilizamos o pacote quanteda, que possui funções de correlação e similaridade entre textos. Você pode ler o guia completo sobre este pacote neste link (em inglês).
library(quanteda)
# Convertendo o formato tidytext em Document-Feature Matrix
esportes_dfm <- esportes_palavras %>%
cast_dfm(modalidade, palavra, n)
# Matriz de Correlação entre os Textos
textstat_simil(esportes_dfm, method = "correlation")## vol2 vol1 vol3 fut2 fut1
## vol1 0.9877202
## vol3 0.9894649 0.9895799
## fut2 0.1600440 0.1631703 0.1573025
## fut1 0.2748133 0.2811887 0.2708432 0.3184908
## fut3 0.2657258 0.2656260 0.2611671 0.3980723 0.3949384O código acima executa duas principais funções:
- A função
cast_dfm()o formato tidytext para o formato Document-Feature Matrix, um formato nativo utilizado pelo pacote quanteda. - A função
textstat_similcalcula as correlações entre os textos. A saída é uma matriz de correlações que mostra o quanto os textos são similares entre si. Quanto mais próximo de 1, mais semelhantes são os textos. Note que os textos de volei são mais similares entre si (maiores correlações). O mesmo acontece entre os textos sobre futebol.
Agrupamento Hierárquico e Visualização
Uma forma mais simples de visualizar a similaridade entre os textos é através da análise de agrupamento hierárquico. Segundo o blog DisplayR:
Agrupamento hierárquico (ou cluster hierárquico), também conhecido como análise de cluster, é um algoritmo que agrupa objetos similares em grupos chamados clusters. O resultado é um conjunto de grupos onde cada grupo é diferente entre si, mas que possui objetos semelhantes dentro de cada grupo.
A forma mais simples de se fazer uma análise de cluster é utilizar métricas de similaridade, que indicam o quanto um objeto é próximo de outro, e assim traçar um dendrograma, que é um gráfico que indica o quão semelhante cada objeto é entre si e como a estrutura de grupos se apresenta. Veja o código abaixo e a saída na forma do dendrograma:
esportes_dfm %>%
textstat_dist(method = "euclidean") %>%
hclust() %>%
plot()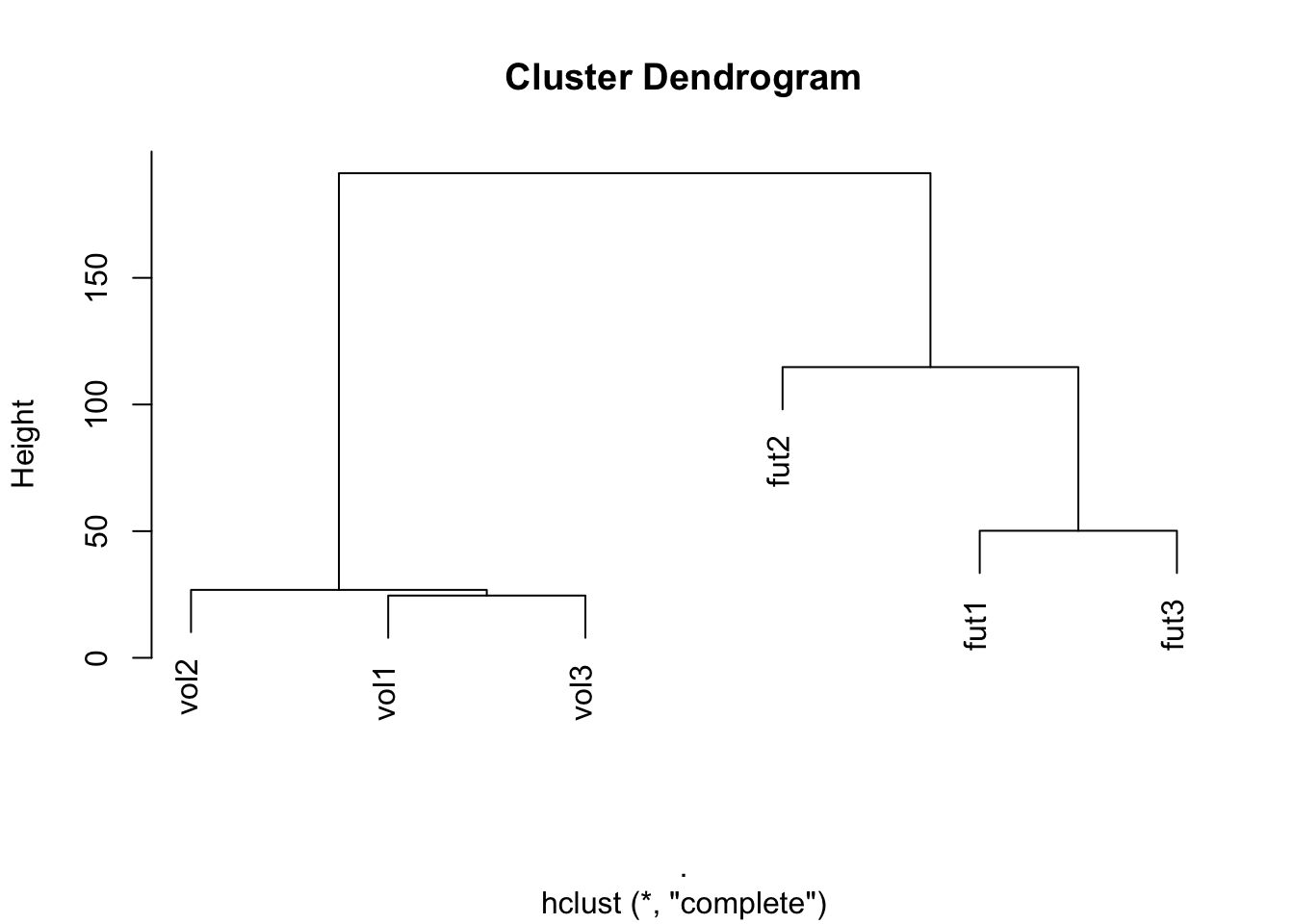
No código acima temos três funções concatenadas. Vamos entender a sequência:
- A função
textstat_dist()do pacote quanteda calcula a matriz de distâncias entre cada um dos textos. O método mais comum utilizado é a distância euclideana, mas outros métodos podem ser utilizamos também de acordo com a natureza dos dados (distância de manhattan, kullback, etc). - Em seguida, aplicamos o algoritmo que agrupa os elementos de acordo com a distância, com a função
hclust()do pacote nativo do R. - Utilizamos a função
plot(), do pacote nativo do R, cuja implementação na funçãohclust()nos mostra o dendrograma para ilustrar a relação entre os textos.
Note que a interpretação fica bem simples sobre as relações entre os textos. É possível visualizar dois grandes grupos conectados - o grupo dos textos de voleibol (vol1, vol2, vol3) e, distante deles, o grupo dos textos de futebol (fut1, fut2, fut3).
Observações Finais
A princípio esta análise parece ser um pouco inócua, pois já sabemos que os textos são de futebol e voleibol antecipadamente. No entanto, este exemplo é claro para ilustrar como estes textos são relacionados entre si. Supondo que você tenha um conjunto de textos sem classificação prévia, você pode simplificar a complexidade de seu problema através de uma análise de agrupamento, onde você agrupará textos semelhantes e, a partir disto, utilizar técnicas descritivas para entender o tema de que se tratam, como frequência de palavras ou tf-idf. Trarei mais exemplos no futuro.
Um abraço e bons estudos!