3. Pré-processamento
Neste artigo você verá algumas técnicas de pré-processamento de textos que você pode utilizar antes de fazer qualquer análise de textos. Estas técnicas são importantes para aumentar o significado que algumas palavras podem trazer para os resultados de suas análises. Aqui vão alguns exemplos:
Em português, as palavras comumente podem ter erros de acentuação. Portanto, uma das técnicas é a troca de letras com acentuação para letras sem acentuação.
Plurais e singulares são importantes para concordância, entretanto no geral trazem o mesmo significado, então dependendo da sua aplicação, pode valer a pena remover os plurais do texto.
Flexões verbais - Também super comum em português, as palavras podem ter flexões de acordo com o tempo verbal, no entanto o significado vem do verbo em si, independente da flexão, de acordo com a aplicação da sua análise. Portanto, reduzir a palavra ao radical pode ser uma boa ideia também.
Stopwords - estas são as palavras que não trazem significado algum ao contexto, como artigos, proposições, etc. Vimos no artigo anterior o impacto disto, então pode ser uma boa ideia remover estas palavras dos textos.
Vamos ver como podemos tratar a seguir as situações mencionadas acima.
Removendo acentos
Para remover acentos, podemos utilizar a função str_replace() do pacote stringr. Veja o exemplo:
library(stringr)
texto <- "Olá mundo"
str_replace(texto, "á", "a")## [1] "Ola mundo"Esta função é bem simples, são 3 parâmetros de entrada:
- A string (ou palavra) onde a substituição será realizada;
- O caracter que deve ser procurado (“á”) e;
- Qual a substituição que deve ser realizada (“a”).
No mundo real, nós temos uma lista de caracteres com acentos que queremos substituir por caracteres sem acentos. Essa transformação pode ser feita usando o código a seguir:
texto = "Olá mundó"
p = c("a","o") # Sequência de caracteres sem acentos
names(p) = c("á","ó") # Sequência de caracteres com acentos
texto %>%
str_replace_all(p)## [1] "Ola mundo"Por fim, para referência, esta é a lista completa de letras acentuadas e a sua substituição para você usar em seus projetos:
p = c("a","e","i","o","u","a","e","i","o","u","a","e","i","o","u","a","o","c")
names(p) = c("á","é","í","ó","ú","à","è","ì","ò","ù","â","ê","î","ô","û","ã","õ","ç")Retornando ao radical
Plurais e singulares, flexões verbais, sufixos e prefixos podem ser tratados todos de uma só vez com o pacote ptstem para a língua portuguesa. Veja o exemplo a seguir:
library(ptstem)
texto <- c("avião", "aviões", "aviação", "viação", "aves", "balão", "balões")
ptstem(texto)## [1] "avião" "avião" "avião" "viação" "aves" "balão" "balão"Um aspecto importante a ser enfocado é que o algoritmo extrai o radical e depois completa todas as palavras de mesmo radical com a forma de maior frequência. Neste exemplo anterior, a palavra aves retorna como aves por esta ser a palavra com maior frequência. O importante aqui é entender que todas as palavras com mesmo radical terão a mesma forma final.
Vamos a mais um exemplo mais focado em flexões verbais:
texto <- c("gosto","gostei","gostamos","gostávamos","gostado","gostará",
"gostaria","gostarão","gosto","gostavamos")
ptstem(texto)## [1] "gosto" "gosto" "gosto" "gosto" "gosto"
## [6] "gosto" "gosto" "gosto" "gosto" "gostavamos"Note que o acento da palavra importa (veja o exemplo com gostávamos e gostavamos), portanto você deve usar o stemming (ou retorno ao radical) antes de remover acentos.
Removendo stopwords
Por fim, remover stopwords é um procedimento simples que podemos executar usando filter() function do pacote dplyr. A lista de stopwords em português pode ser adquirida no pacote tm:
library(tm)
stopwords(kind = "pt")## [1] "de" "a" "o" "que"
## [5] "e" "do" "da" "em"
## [9] "um" "para" "com" "não"
## [13] "uma" "os" "no" "se"
## [17] "na" "por" "mais" "as"
## [21] "dos" "como" "mas" "ao"
## [25] "ele" "das" "à" "seu"
## [29] "sua" "ou" "quando" "muito"
## [33] "nos" "já" "eu" "também"
## [37] "só" "pelo" "pela" "até"
## [41] "isso" "ela" "entre" "depois"
## [45] "sem" "mesmo" "aos" "seus"
## [49] "quem" "nas" "me" "esse"
## [53] "eles" "você" "essa" "num"
## [57] "nem" "suas" "meu" "às"
## [61] "minha" "numa" "pelos" "elas"
## [65] "qual" "nós" "lhe" "deles"
## [69] "essas" "esses" "pelas" "este"
## [73] "dele" "tu" "te" "vocês"
## [77] "vos" "lhes" "meus" "minhas"
## [81] "teu" "tua" "teus" "tuas"
## [85] "nosso" "nossa" "nossos" "nossas"
## [89] "dela" "delas" "esta" "estes"
## [93] "estas" "aquele" "aquela" "aqueles"
## [97] "aquelas" "isto" "aquilo" "estou"
## [101] "está" "estamos" "estão" "estive"
## [105] "esteve" "estivemos" "estiveram" "estava"
## [109] "estávamos" "estavam" "estivera" "estivéramos"
## [113] "esteja" "estejamos" "estejam" "estivesse"
## [117] "estivéssemos" "estivessem" "estiver" "estivermos"
## [121] "estiverem" "hei" "há" "havemos"
## [125] "hão" "houve" "houvemos" "houveram"
## [129] "houvera" "houvéramos" "haja" "hajamos"
## [133] "hajam" "houvesse" "houvéssemos" "houvessem"
## [137] "houver" "houvermos" "houverem" "houverei"
## [141] "houverá" "houveremos" "houverão" "houveria"
## [145] "houveríamos" "houveriam" "sou" "somos"
## [149] "são" "era" "éramos" "eram"
## [153] "fui" "foi" "fomos" "foram"
## [157] "fora" "fôramos" "seja" "sejamos"
## [161] "sejam" "fosse" "fôssemos" "fossem"
## [165] "for" "formos" "forem" "serei"
## [169] "será" "seremos" "serão" "seria"
## [173] "seríamos" "seriam" "tenho" "tem"
## [177] "temos" "tém" "tinha" "tínhamos"
## [181] "tinham" "tive" "teve" "tivemos"
## [185] "tiveram" "tivera" "tivéramos" "tenha"
## [189] "tenhamos" "tenham" "tivesse" "tivéssemos"
## [193] "tivessem" "tiver" "tivermos" "tiverem"
## [197] "terei" "terá" "teremos" "terão"
## [201] "teria" "teríamos" "teriam"Exemplo completo
Vamos resgatar o exemplo do artigo anterior e aplicar o pré-processamento antes de realizar o gráfico de frequência de palavras mais citadas no artigo da Wikipedia:
library(dplyr)
library(tidytext)
library(tm)
library(ggplot2)
texto = "
São Paulo possui o maior PIB dentre as cidades brasileiras, o décimo maior do mundo e, segundo projeção da PricewaterhouseCoopers, será o sexto maior em 2025.[16] Segundo dados do Instituto Brasileiro de Geografia e Estatística (IBGE), em 2016, seu Produto Interno Bruto (PIB) foi de 687 035 889,61 reais, o que equivale a cerca de 11% do PIB brasileiro, 34% do PIB, assim como 36% de toda a produção de bens e serviços, do estado de São Paulo,[147] e 21% da economia da região sudeste.[148]
De acordo com uma pesquisa divulgada Federação do Comércio de Bens, Serviços e Turismo do Estado de São Paulo (Fecomercio), se fosse um país, a cidade de São Paulo poderia ser classificada como a 36.ª maior economia do mundo, acima de nações como Portugal, Finlândia e Hong Kong. De acordo com o mesmo estudo, o município sedia 63% dos grupos internacionais instalados no país e 17 dos 20 maiores bancos.[149]
Sua região metropolitana possui um PIB de cerca de 613 bilhões de reais (dados de 2009).[150] Segundo dados do IBGE, a rede urbana de influência exercida pela cidade no resto do país abrange 28% da população e 40,5% do PIB brasileiro.[151]
A capital paulista é a sexta cidade do mundo em número de bilionários, segundo a listagem da revista Forbes considera como referência o endereço principal dos 1 210 bilionários da lista de 2011 feita pela revista, com base em valores convertidos para o dólar norte-americano.[152] Entretanto, a crise financeira de 2008-2009 afetou a renda média domiciliar per capita dos moradores de São Paulo, que, em 2008, era de 816,40 reais, o que posiciona a cidade na oitava colocação no ranking das capitais brasileiras, atrás de Florianópolis, Porto Alegre, Vitória, Brasília, Curitiba, Rio de Janeiro e Belo Horizonte.[153]
Segundo pesquisa da consultoria Mercer sobre o custo de vida para funcionários estrangeiros, São Paulo está entre as dez cidades mais caras do mundo, classificada na décima posição em 2011, 11 postos acima de sua classificação de 2010, e na frente de cidades como Londres, Paris, Milão e Nova Iorque.[154][155]
Edifícios comerciais na Avenida Paulista
Vista da região do Itaim Bibi.
Rua Oscar Freire, na região dos Jardins, eleita a oitava rua mais luxuosa do planeta[156]
Um dos maiores centros financeiros do Brasil e do mundo, São Paulo passa hoje por uma transformação em sua economia. Durante muito tempo a indústria constituiu uma atividade econômica bastante presente na cidade, porém São Paulo tem atravessado nas últimas três décadas uma clara mudança em seu perfil econômico: de uma cidade com forte caráter industrial, o município tem cada vez mais assumido um papel de cidade terciária, pólo de serviços e negócios para o país. Em São Paulo, por exemplo, está sediada a B3 (sigla de Brasil, Bolsa, Balcão), a bolsa oficial do Brasil. A B3 tinha em 2017, um patrimônio de 13 bilhões de dólares.[21] São Paulo ficou em segundo lugar depois de Nova Iorque no ranking bi-anual da revista FDI das \"Cidades do Futuro\" 2013/14 nas Américas, e foi nomeada a cidade latino-americana do Futuro 2013/14, ultrapassando a Santiago de Chile, a primeira cidade na classificação anterior. Santiago agora ocupa o segundo lugar, seguido por Rio de Janeiro,[157] o estudo também indica que São Paulo recebeu mais Investimentos Estrangeiros Diretos que Nova Iorque.[158]
O município tem alguns centros financeiros espalhados por seu território, concentrados na região das subprefeituras da Sé, Pinheiros e Santo Amaro. O principal e mais famoso deles a avenida Paulista, que abriga sedes de bancos, multinacionais, hotéis, consulados e se impõe como um dos principais pontos turísticos e culturais da cidade. O centro da cidade, que apesar de ter sido ofuscado pelas centralidades econômicas mais recentes, abriga a bolsa de valores, diversas empresas e hotéis. Além destes, outras regiões que se destacam por sua intensa e moderna verticalização, pela presença de hotéis de luxo e empresas multinacionais são as regiões das avenidas Brigadeiro Faria Lima e Luís Carlos Berrini.[159]
Muitos analistas também têm apontado São Paulo como uma importante \"cidade global\" (ou \"metrópole global\", classificação dividida apenas com o Rio de Janeiro entre as cidades brasileiras[160]). Como cidade global, São Paulo tem acesso às principais rotas aeroviárias mundiais, às principais redes de informação, assim como sedia filiais de empresas transnacionais de importância global, além de importantes instituições financeiras, mesmo estando conectada marginalmente aos fluxos transnacionais de pessoas, investimentos e empregos.[161]
O urbanista João Sette Whitaker Ferreira, entretanto, considera que a desigualdade social e a segregação espacial descaracterizam São Paulo como uma cidade global.[162] Apesar de ser o centro financeiro do país, São Paulo apresenta também alto índice de negócios ligados à economia informal.[163] Neste mesmo cenário, segundo dados de 2001 da prefeitura do município,[164] cerca de 10% dos paulistanos vivia abaixo da linha de pobreza.
A cidade de São Paulo também tem se consolidado em um polo de comércio de produtos contrabandeados, pirateados e falsificados,[165] em geral localizados em alguns pontos do centro da cidade como a Rua 25 de Março, a rua Santa Ifigênia e áreas próximas a estações de metrô. Os artigos em geral são CDs com versões piratas de softwares, filmes ou álbuns em CD e DVD,[166] ou então acessórios e itens de vestuário, principalmente mochilas e tênis de marcas internacionais, entre outros artigos. Nos últimos anos, porém, tem crescido a apreensão desses artigos pirateados.[167]
"
wiki = tibble(linha = 1, texto = ptstem(texto)) # Retorno ao radical
wiki <- wiki %>%
unnest_tokens(palavra, texto) %>%
filter(!palavra %in% stopwords(kind = "pt")) %>% # Removendo stopwords
count(palavra, sort = TRUE) %>% # Contar palavras distintas
mutate(palavra = reorder(palavra, n)) %>% # Manter a ordenação de frequência para o gráfico
top_n(10) %>%
ggplot(aes(palavra, n)) +
geom_col() +
xlab(NULL) +
coord_flip()
wiki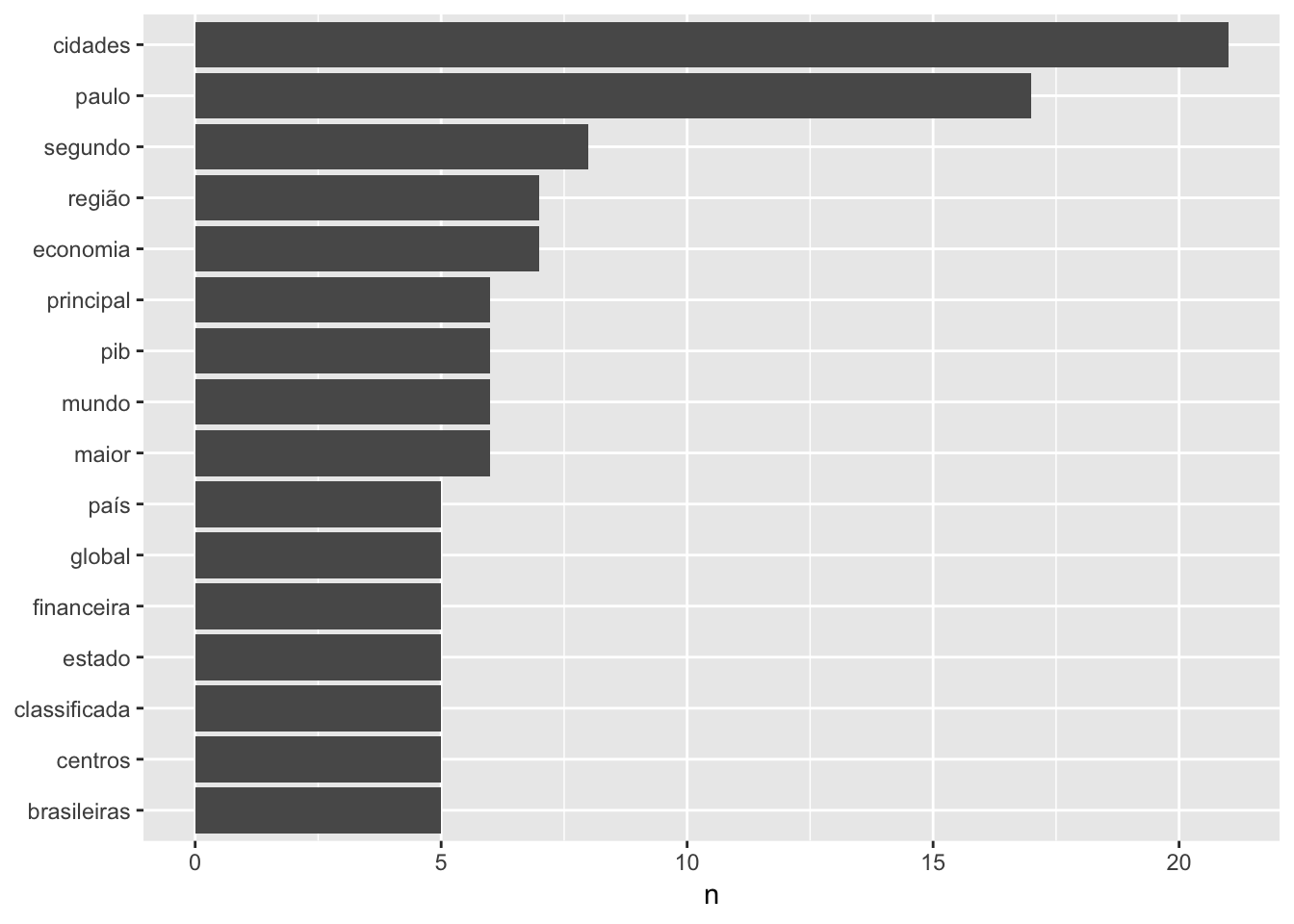
Note que este artigo da Wikipedia trata da cidade de São Paulo e sua economia. Temos duas principais considerações sobre o gráfico acima:
- Neste exemplo, por se tratar de um conteúdo oficial, optei por não remover os acentos pois erros no texto são pouco prováveis.
- A palavra paulo é a segunda mais frequente e deveria vir junto a são. No entanto, são foi removido por ser uma stopword.
- Podemos ver algumas palavras mais frequentes relacionados a economia: economia, pib e financeira. Se não soubessemos de ante-mão que este texto era sobre economia, teríamos alguns fortes indícios disso.
Considerações Finais
Estes procedimentos são fundamentais na análise e mineração de textos. Apesar de um pouco extenso em termos de comandos e tratamentos, eles trazem um ganho de informação muito grande na aplicação dos métodos mais avançados de análise, como você verá nos próximos artigos.
Um abraço e bons estudos!